主要使用 GGUF 量化模型减少显存占用,同时使用 llama.cpp 运行模型。
部署模型
- pull llama.cpp 镜像
1
docker pull ghcr.io/ggml-org/llama.cpp:server-cuda
- 下载模型
1
huggingface-cli download Hack337/UI-TARS-1.5-7B-GGUF --local-dir /data/ui-tars/models/UI-TARS-1.5-7B-GGUF
- 启动容器
1
docker run -d -it --name ui-tars --gpus all -v /data/ui-tars/models:/models -p 8000:8000 ghcr.io/ggml-org/llama.cpp:server-cuda --port 8000 --host 0.0.0.0 -m /models/UI-TARS-1.5-7B-GGUF/UI-TARS-1.5.gguf --mmproj /models/UI-TARS-1.5-7B-GGUF/mmproj-model-f16.gguf -a ui-tars-1.5-7B --api-key xxxx -c 128000 --threads 10
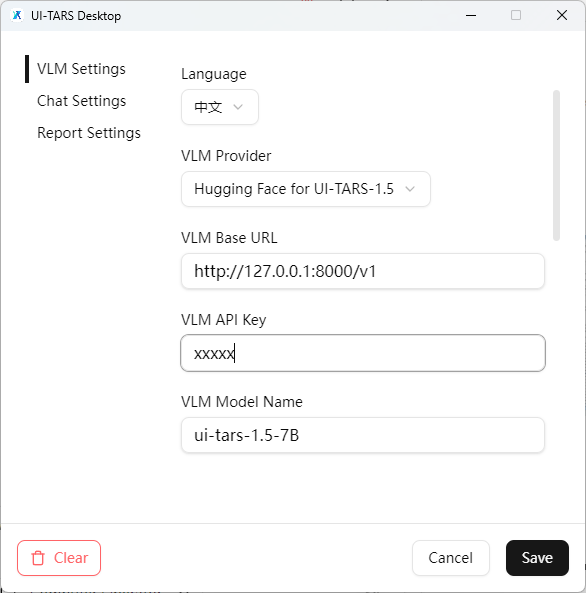
配置 UI-Tars-Desktop