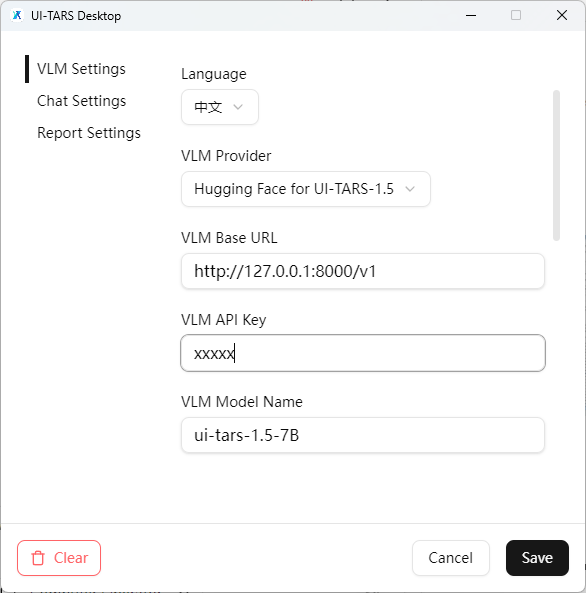
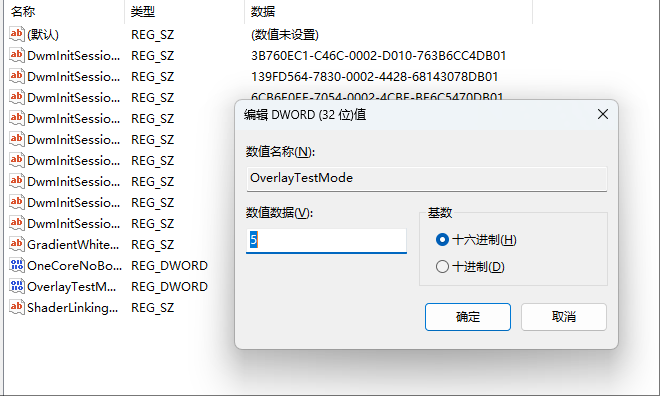
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| import io
import logging
import os
import platform
import sys
import time
from datetime import datetime
import pyautogui
from PIL import Image
from gui_agents.s2.agents.agent_s import AgentS2
from gui_agents.s2.agents.grounding import OSWorldACI
def scale_screen_dimensions(width: int, height: int, max_dim_size: int):
scale_factor = min(max_dim_size / width, max_dim_size / height, 1)
safe_width = int(width * scale_factor)
safe_height = int(height * scale_factor)
return safe_width, safe_height
def run_agent(agent, instruction: str, scaled_width: int, scaled_height: int):
obs = {}
traj = "Task:\n" + instruction
subtask_traj = ""
for _ in range(15):
screenshot = pyautogui.screenshot()
screenshot = screenshot.resize((scaled_width, scaled_height), Image.LANCZOS)
buffered = io.BytesIO()
screenshot.save(buffered, format="PNG")
screenshot_bytes = buffered.getvalue()
obs["screenshot"] = screenshot_bytes
info, code = agent.predict(instruction=instruction, observation=obs)
if "done" in code[0].lower() or "fail" in code[0].lower():
if platform.system() == "Darwin":
os.system(
f'osascript -e \'display dialog "Task Completed" with title "OpenACI Agent" buttons "OK" default button "OK"\''
)
elif platform.system() == "Linux":
os.system(
f'zenity --info --title="OpenACI Agent" --text="Task Completed" --width=200 --height=100'
)
agent.update_narrative_memory(traj)
break
if "next" in code[0].lower():
continue
if "wait" in code[0].lower():
time.sleep(5)
continue
else:
time.sleep(1.0)
print("EXECUTING CODE:", code[0])
exec(code[0])
time.sleep(1.0)
traj += (
"\n\nReflection:\n"
+ str(info["reflection"])
+ "\n\n----------------------\n\nPlan:\n"
+ info["executor_plan"]
)
subtask_traj = agent.update_episodic_memory(info, subtask_traj)
current_platform = platform.system().lower()
screen_width, screen_height = pyautogui.size()
scaled_width, scaled_height = scale_screen_dimensions(
screen_width, screen_height, max_dim_size=2400
)
engine_params = {"engine_type": 'openai', "model": "doubao-1.5-vision-pro-250328"}
engine_params_for_grounding = {
"engine_type": "openai",
"model": "doubao-1.5-vision-pro-250328",
"grounding_width": grounding_width,
"grounding_height": screen_height
* grounding_width
/ screen_width,
}
grounding_agent = OSWorldACI(
platform=current_platform,
engine_params_for_generation=engine_params,
engine_params_for_grounding=engine_params_for_grounding,
width=screen_width,
height=screen_height,
)
agent = AgentS2(
engine_params,
grounding_agent,
platform=current_platform,
action_space="pyautogui",
observation_type="mixed",
search_engine=None,
)
if __name__ == '__main__':
while True:
query = input("Query: ")
agent.reset()
run_agent(agent, query, scaled_width, scaled_height)
response = input("Would you like to provide another query? (y/n): ")
if response.lower() != "y":
break
|